So far, we have proven that Data Science is not only for
business, marketing and advertising, but can have practical uses for various
types of fields in Science, ranging from Astronomy to Physics, and beyond. But
the examples presented are just the beginning.
We have ascertained how Data Science can be useful in the
pursuit of scientific discoveries, but now it is time to review the vanguard of
the industry, where it is headed, what does the future holds and what might be
some roadblocks to those ends.
Deep learning the future
The concept of deep learning is based of neural networks,
which has been around for a long time (Roberts, 2014) , but it has taken
speed in the latest years, with corporations and universities investing in multi-layer neural networks destined for the
most varied of uses.
Without going much further, we can mention the much
mentioned project Google Deepmind, which has developed things like human-level
control deep reinforcement learning and many other projects (Google Deepmind, 2011) .

Figure 1
– Example of how deep learning works for face recognition (Mayer, 2015)
But maybe the most impressive and well known feat achieved
by the project is the development of a deep learning program that managed to
learn the complex game of Go, and defeated the top Go player, Lee Sedol, in a
5-match competition (Gibney, 2016) . This is an accomplishment that shows
how much Deep Learning has advanced, since experts said that a computer would
never beat a human player (Cho, 2016) .
That’s why deep learning is being experimented on cell
classification (Chen, et al., 2016) , chemical mappings, x-ray
scattering image classifications and many more (Brookhaven National Laboratory, 2015) . Even major
universities and research centers are investing in deep learning, like NERSC
and Berkeley joining forces to test the capacity of the technology with health
and medicine breakthroughs (Kincade, 2015) .
Data Science as an aid of human knowledge broadening
With science advancing in giant leaps in several fields, and
instruments getting more powerful and sophisticated, the amount of data to
process is getting bigger and bigger. That is where data science comes into the
scene.
The detection of gravitational waves is one of the biggest
headlines in scientific discovery in the past months (Overbye, 2016) , confirming a 100-year old Einstein
theory. But the fact is that the Laser Interferometer Gravitational-Wave
Observatory received a particular strong signal that managed to confirm the
theory, a feat that proved difficult because of the difficulty of discerning
signals from noise. That is how Data Science could help make this separation of
signals from noise easier by finding underlying evidence by processing the
outstanding amount of data produced by their equipment (Yuan, 2016) .

Figure 2
– Consistent signals detected in LIGO sites located 2000 miles apart (Circus Bazaar, 2016)
And it is worth mentioning how Data Science could help
Astronomy. As telescopes get more complex and sensitive to light, the amount of
data gathered is getting larger and unmanageable. That is the reason several
projects are using Data mining to recognize celestial bodies, to try to keep up
with the data production (Galaxy Zoo, 2016) .
But it is not a paved road ahead
As sciences advances, so does the fear that humans will be
replaced by robots. With predictions of computers with advanced neural networks
replacing entry level lawyers (Kravets, 2015) , and advances made with IBM Watson learning
case histories of hospitals to learn what diagnoses and treatments to recommend
(Cohn, 2013) ,
there is a concern about how the advancements of Data Science are going to
affect the rest of the population.
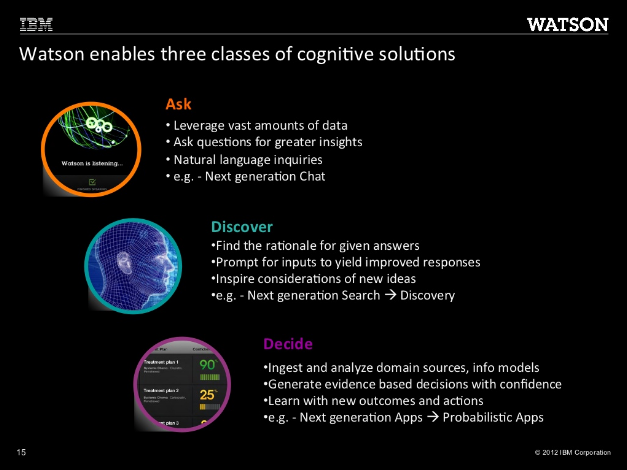
Figure 3
– Example of IBM Watson’s healthcare capabilities (Saxena, 2012)
Also, for data science to thrive, it needs data. And because
scientific papers, research and publications are so difficult or expensive to
get a hold of (The Cost of Knowledge, 2012) , sometimes the raw data
or sources necessary to discover something novel is somewhat of an utopia; with
publishing companies charging enormous amounts to get a glimpse of their
material (Elbakyan, 2015) .
Data Science’s has yet no bounds
While there are still titanic challenges in the sciences
that Data Science is yet to conquest, there are breakthroughs made by the day,
trying to overcome shortcomings and achieve a better understanding in several
fields of science (Prabhat, 2015) .
So the future looks bright for Data Science, showing
significant increase of demand of people expert in the field (Islam, 2015) ,
a number of companies getting into the game and being a participant an active
participant of scientific discoveries. It is to be seen how bright it can be (NeRSC, 2015) .
Bibliography
Brookhaven National Laboratory, 2015. Deep
Learning for Analysis of Materials Science Data. [Online]
Available at: https://www.bnl.gov/compsci/projects/deep-learning.php
[Accessed June 2016].
Available at: https://www.bnl.gov/compsci/projects/deep-learning.php
[Accessed June 2016].
Chen, C. L.
et al., 2016. Deep Learning in Label-free Cell Classification. [Online]
Available at: http://www.nature.com/articles/srep21471
[Accessed June 2016].
Available at: http://www.nature.com/articles/srep21471
[Accessed June 2016].
Cho, A.,
2016. Computer that mimics human brain beats professional at game of Go. [Online]
Available at: http://www.sciencemag.org/news/2016/01/huge-leap-forward-computer-mimics-human-brain-beats-professional-game-go
[Accessed June 2016].
Available at: http://www.sciencemag.org/news/2016/01/huge-leap-forward-computer-mimics-human-brain-beats-professional-game-go
[Accessed June 2016].
Circus
Bazaar, 2016. On Einsten's Gravitational Waves: The Paper. [Online]
Available at: http://www.circusbazaar.com/on-einsteins-gravitational-waves-the-paper/
[Accessed June 2016].
Available at: http://www.circusbazaar.com/on-einsteins-gravitational-waves-the-paper/
[Accessed June 2016].
Cohn, J.,
2013. The Robot Will See You Now. The atlantic, March.Issue March 2013
Issue.
Elbakyan,
A., 2015. Sci-Hub Reply. [Online]
Available at: https://torrentfreak.com/images/sci-hub-reply.pdf
[Accessed June 2016].
Available at: https://torrentfreak.com/images/sci-hub-reply.pdf
[Accessed June 2016].
Galaxy Zoo,
2016. Galaxy Zoo. [Online]
Available at: https://www.galaxyzoo.org/
[Accessed June 2016].
Available at: https://www.galaxyzoo.org/
[Accessed June 2016].
Gibney, E.,
2016. Google AI algorithm masters ancient game of Go. [Online]
Available at: http://www.nature.com/news/google-ai-algorithm-masters-ancient-game-of-go-1.19234
[Accessed June 2016].
Available at: http://www.nature.com/news/google-ai-algorithm-masters-ancient-game-of-go-1.19234
[Accessed June 2016].
Google
Deepmind, 2011. Publications. [Online]
Available at: https://deepmind.com/publications
[Accessed June 2016].
Available at: https://deepmind.com/publications
[Accessed June 2016].
Islam, M.,
2015. Future of Data Science and Data Scientists. [Online]
Available at: https://www.linkedin.com/pulse/future-data-science-scientist-mohammad-islam
[Accessed June 2016].
Available at: https://www.linkedin.com/pulse/future-data-science-scientist-mohammad-islam
[Accessed June 2016].
Kincade, K.,
2015. NERSC, Berkeley Lab Explore Frontiers of Deep Learning for Science. [Online]
Available at: http://www.nersc.gov/news-publications/nersc-news/science-news/2015/nersc-berkeley-lab-explore-frontiers-of-deep-learning-for-science/
[Accessed June 2016].
Available at: http://www.nersc.gov/news-publications/nersc-news/science-news/2015/nersc-berkeley-lab-explore-frontiers-of-deep-learning-for-science/
[Accessed June 2016].
Kravets, D.,
2015. Law firm bosses envision Watson-type computers replacing young
lawyers. [Online]
Available at: http://arstechnica.com/tech-policy/2015/10/law-firm-bosses-envision-watson-type-computers-replacing-young-lawyers/
[Accessed June 2016].
Available at: http://arstechnica.com/tech-policy/2015/10/law-firm-bosses-envision-watson-type-computers-replacing-young-lawyers/
[Accessed June 2016].
Mayer, R.,
2015. Deep Learning Smarts Up Your Smart Phone. [Online]
Available at: http://www.amax.com/blog/wp-content/uploads/2015/12/blog_deeplearning3.jpg
[Accessed June 2016].
Available at: http://www.amax.com/blog/wp-content/uploads/2015/12/blog_deeplearning3.jpg
[Accessed June 2016].
NeRSC, 2015.
Berkeley Lab Climate Software Honored for Pattern Recognition Advances. [Online]
Available at: https://www.nersc.gov/news-publications/nersc-news/nersc-center-news/2015/berkeley-lab-climate-software-honored-for-pattern-recognition-advances/
[Accessed June 2016].
Available at: https://www.nersc.gov/news-publications/nersc-news/nersc-center-news/2015/berkeley-lab-climate-software-honored-for-pattern-recognition-advances/
[Accessed June 2016].
Overbye, D.,
2016. Gravitational Waves Detected, Confirming Einstein’s Theory. [Online]
Available at: http://mobile.nytimes.com/2016/02/12/science/ligo-gravitational-waves-black-holes-einstein.html
[Accessed June 2016].
Available at: http://mobile.nytimes.com/2016/02/12/science/ligo-gravitational-waves-black-holes-einstein.html
[Accessed June 2016].
Prabhat,
2015. Big science problems, big data solutions. [Online]
Available at: https://www.oreilly.com/ideas/big-science-problems-big-data-solutions
[Accessed June 2016].
Available at: https://www.oreilly.com/ideas/big-science-problems-big-data-solutions
[Accessed June 2016].
Roberts, E.,
2014. Neural Networks History: The The 1940's to the 1970's. [Online]
Available at: https://cs.stanford.edu/people/eroberts/courses/soco/projects/neural-networks/History/history1.html
[Accessed June 2016].
Available at: https://cs.stanford.edu/people/eroberts/courses/soco/projects/neural-networks/History/history1.html
[Accessed June 2016].
Saxena, M.,
2012. Putting IBM Watson to Work. [Online]
Available at: http://www.slideshare.net/manojsaxena2/putting-ibm-watson-to-work-saxena
[Accessed June 2016].
Available at: http://www.slideshare.net/manojsaxena2/putting-ibm-watson-to-work-saxena
[Accessed June 2016].
The Cost of
Knowledge, 2012. Statement of Purpose. [Online]
Available at: https://gowers.files.wordpress.com/2012/02/elsevierstatementfinal.pdf
[Accessed June 2016].
Available at: https://gowers.files.wordpress.com/2012/02/elsevierstatementfinal.pdf
[Accessed June 2016].
Yuan, M.,
2016. Gravitational Wave Ushers in a New Wave of Data Science. [Online]
Available at: https://austinstartups.com/gravitational-wave-ushers-in-a-new-wave-of-data-science-928d620d727#.8x5fq0g9i
[Accessed June 2016].
Available at: https://austinstartups.com/gravitational-wave-ushers-in-a-new-wave-of-data-science-928d620d727#.8x5fq0g9i
[Accessed June 2016].









